On Computational Social Science
19 Feb 2014Computational Social Science is a new phrase that people throw around a lot–I even call myself that explicitly here on my website. I’d like to get my perspective on what it means to me written down.
One thing to keep in mind is that it’s clearly not the best possible name for the kind of science that I (and many others) do. But those of us who self-identify as CSSs are mostly trained in social/computer sciences and care about academic audiences, so we needed a term other than data scientist. This one is catching on and I’m going with it.
In a way, the most unfortunate part of the term is that it puts the method (computational) before the social science (credit to Duncan Watts for this thought). In this way, it emphasizes how you are doing science rather than what questions you are attempting to answer. But actually, the distinction about methods is often the salient one. Being a creator (or early adopter) of methods allows you to do science in a way that wasn’t possible before. The innovation in CSS comes from what new knowledge is made possible through technology – we are often asking the same basic questions that social scientists have asked for a long time, but now we are just better equipped to answer them.
To illustrate this, I came up with this crude model of how new technology affects the production of scientific knowledge. On the y-axis measurement technology, enabled by new instrumentation or statistical techniques that let us measure more constructs, more precisely, about more people. On the x-axis is our level of experimental control. Technology allows us to exert greater control over social systems (especially those which are digital), changing the structures of interactions in ways that allow us to gain knowledge of the underlying causal structure.
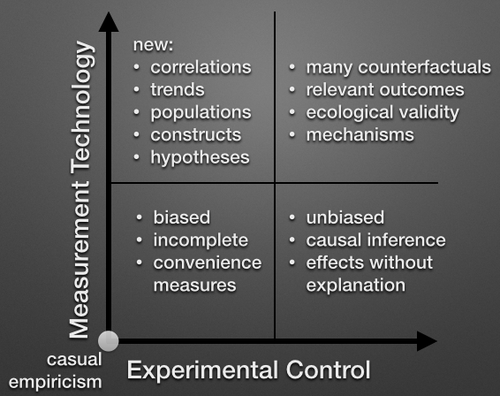
At the origin, we have casual empiricism: social science with no ability to measure anything well and no ability to effect a change in the environment. Basically, what you and I do every day :)
As we move up and to the right on this plot, we gain the ability to more satisfyingly answer important questions. This is the essence of CSS. As we innovate in measurement/control, we end up being able to produce higher quality, more complete, and more accurate social scientific knowledge, even if the underlying questions haven’t changed.
Where does theory fit in here? I won’t go so far as to say that we don’t need theory anymore. There is nothing in this shifting production possibility frontier that conflicts with the Popperian conception of scientific progress. However, I would posit that with better measurement/control we should shift our effort away from spending more time thinking deductively and theorizing toward thinking empirically and directly testing the specific, often highly contextual, questions we have as social scientists.
Update: Some insightful responses via Twitter.
Kevin Collins pointed out that my “measurement” dimension conflates a lot of different things. He offered these expanded dimensions:
@seanjtaylor I’d say there are four relevant dims: external validity, internal validity, “Richness of data,” “Scale of data,”
— Kevin Collins (@kwcollins) February 19, 2014
Michael Tofias took issue with my discussion of the diminished role of theory with better technolgy. I’m open minded that we could probably use a more theoretical grounding here but I’ve yet to see use it as a compelling complement to innovation in measurement/experiments.
@seanjtaylor @drewconway couldn’t agree less. Explicit theorizing needed now more than ever.
— Michael Tofias (@tofias) February 19, 2014
There’s obviously a nice middle ground here where we don’t let the increase in data lead to “theory gone wild.”
@tofias @SolomonMg @seanjtaylor @drewconway exciting time to test existing theory while being thoughtful in the creation of new theory
— Tristan Botelho (@TBotelho1) February 19, 2014
Kim Weeden asked good questions about what differentiates CSS from SS.
@seanjtaylor 1) How are correlations etc (UL quadrant) “new”? 2) What differentiates CSS from SS, some of which in UR, LR quads? Just size?
— Kim Weeden (@WeedenKim) February 19, 2014
My reply to the last two questions:
- if we observe a new correlation between two previously unmeasured variables, then it’s new knowledge about the world.
- For me it’s pushing upward-rightward by early adoption of new technologies, using those innovations to get better answers.